At this stage, AgenticMediaLab has evolved into something much more than:
- a content collector
- an AI summarizer
- a workflow experiment
The platform now has:
- ingestion pipelines
- async queues
- LangGraph orchestration
- embeddings
- semantic storage with pgvector
The next major capability is:
trend intelligence.
Because collecting information is not enough.
Autonomous AI systems increasingly need to answer:
What matters right now?
This is where trend ranking becomes critical.
In this article, we will build the first AI trend ranking engine for AgenticMediaLab using:
- embeddings
- semantic similarity
- recency scoring
- velocity analysis
- PostgreSQL
- pgvector
This is the beginning of the platform’s intelligence layer.
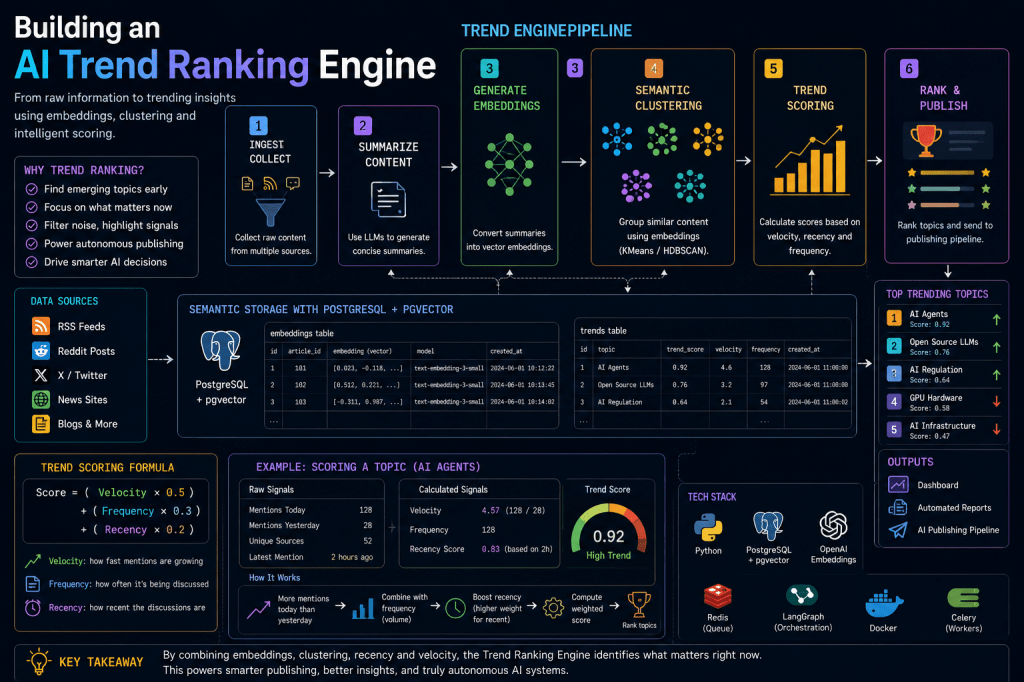
Why Trend Detection Matters
Modern information systems process enormous amounts of content.
Without ranking systems:
- everything appears equally important
- signals get buried
- emerging topics become invisible
AI trend ranking engines help systems identify:
- momentum
- clustering
- topic acceleration
- semantic convergence
This enables:
- autonomous news detection
- AI media analysis
- intelligent publishing decisions
The Core Problem
Suppose the platform ingests:
- 2,000 AI articles per day
- 15,000 Reddit posts
- hundreds of RSS feeds
- X/Twitter discussions
How does the system determine:
- which topics are becoming important?
Keyword counting alone is insufficient.
The system needs:
- semantic grouping
- recency weighting
- frequency analysis
- velocity detection
High-Level Trend Architecture
The new workflow layer looks like this:
RSS Feeds ↓Summarization ↓Embeddings ↓Semantic Clustering ↓Trend Scoring ↓Ranking Engine ↓Publishing Pipeline
This transforms the platform into:
- an AI intelligence system.
What Makes Something “Trending”?
Trend ranking is more complex than:
- counting mentions.
The system should evaluate:
- semantic similarity
- growth velocity
- recency
- source diversity
- engagement signals
- topic acceleration
A topic discussed:
- 3 times yesterday
- 40 times today
may be more important than:
- a topic consistently mentioned 20 times daily.
Trend systems measure change.
Repository Structure
Create:
trends/│├── cluster_articles.py├── trend_score.py├── ranking_engine.py└── trend_pipeline.py
This becomes the intelligence layer.
Step 1 — Fetch Recent Embeddings
Create:
trends/cluster_articles.py
Example:
import psycopg2connection = psycopg2.connect( host="localhost", database="agentic_media_lab", user="postgres", password="password")cursor = connection.cursor()query = """SELECT article_id, embeddingFROM embeddingsLIMIT 100"""cursor.execute(query)results = cursor.fetchall()print(len(results))
This loads semantic vectors from PostgreSQL.
Why Embeddings Matter for Trends
Embeddings allow the system to identify:
- semantically related discussions
instead of:
- exact keyword matches.
Example:
OpenAI launches agent platform
and:
New autonomous workflow system released
may belong to the same emerging trend.
Keyword systems often miss this.
Embeddings capture meaning.
Step 2 — Semantic Clustering
Install dependency:
pip install scikit-learn
KMeans Clustering Example
Update:
trends/cluster_articles.py
Example:
from sklearn.cluster import KMeansvectors = [row[1] for row in results]kmeans = KMeans( n_clusters=5, random_state=42)kmeans.fit(vectors)labels = kmeans.labels_print(labels)
This groups articles into:
- semantic topic clusters.
What Is Clustering?
Clustering automatically groups:
- similar semantic vectors
into:
- topic categories
without predefined labels.
This enables:
- unsupervised trend discovery.
Example Cluster Topics
The system might automatically discover:
Cluster 1 → AI AgentsCluster 2 → Open Source ModelsCluster 3 → GPU HardwareCluster 4 → AI RegulationCluster 5 → AI Infrastructure
This happens through semantic similarity.
Step 3 — Calculating Trend Velocity
Create:
trends/trend_score.py
Example:
def calculate_velocity( mentions_today, mentions_yesterday): if mentions_yesterday == 0: return mentions_today return ( mentions_today / mentions_yesterday )
Why Velocity Matters
Trend systems care about:
- acceleration
not just:
- popularity.
Example:
Yesterday → 5 mentionsToday → 50 mentions
This indicates:
- emerging momentum.
Step 4 — Recency Weighting
Recent articles should influence trends more heavily.
Example:
from datetime import datetimedef recency_score(hours_old): return max( 0, 24 - hours_old )
Recent discussions become:
- more influential.
Step 5 — Combined Trend Score
Example:
def trend_score( velocity, frequency, recency): return ( velocity * 0.5 + frequency * 0.3 + recency * 0.2 )
This creates:
- weighted ranking logic.
Why Weighted Ranking Matters
Trend systems require balancing:
- frequency
- freshness
- momentum
Otherwise:
- old topics dominate
OR - noisy spikes dominate
Ranking becomes an engineering discipline.
Creating the Trends Table
Update PostgreSQL schema:
CREATE TABLE trends ( id SERIAL PRIMARY KEY, topic TEXT, trend_score FLOAT, velocity FLOAT, frequency INTEGER, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
This becomes the trend intelligence memory layer.
Storing Trend Scores
Create:
trends/ranking_engine.py
Example:
query = """INSERT INTO trends ( topic, trend_score, velocity, frequency)VALUES (%s, %s, %s, %s)"""
The system can now persist:
- historical trend evolution.
Why Historical Trends Matter
Over time the platform can analyze:
- trend acceleration
- decay curves
- topic persistence
- recurring discussions
This transforms the platform into:
- a temporal intelligence system.
Example Future Workflow
The architecture is evolving into:
Collect News ↓Generate Embeddings ↓Semantic Clustering ↓Trend Ranking ↓AI Publishing ↓Social Distribution
The system increasingly behaves like:
- an autonomous media organization.
Adding LangGraph Orchestration
Soon the trend engine will integrate directly into:
- LangGraph workflows.
Example:
Collect ↓Summarize ↓Embed ↓Cluster ↓Score Trends ↓Generate Social Posts
This creates:
- fully autonomous AI pipelines.
Why Trend Detection Is Hard
Trend systems are noisy.
Challenges include:
- duplicate content
- spam
- viral bursts
- stale topics
- semantic drift
- inconsistent data sources
This is why modern trend engines increasingly rely on:
- embeddings
- semantic clustering
- recency models
- ranking algorithms
instead of:
- simple keyword counting.
The Bigger Shift
At this point the platform is evolving from:
- automation
into:
- intelligence.
The system is no longer simply:
- processing information
It is beginning to:
- interpret importance.
This is a major architectural milestone.
Common Beginner Mistake
Many beginner systems implement trends like this:
Count keyword mentions
But production systems increasingly use:
- semantic similarity
- clustering
- ranking models
- embeddings
- recency weighting
Trend intelligence becomes a full subsystem.
Future Improvements
The trend engine will eventually support:
- semantic duplicate detection
- anomaly detection
- cross-platform ranking
- sentiment weighting
- engagement scoring
- topic forecasting
This moves toward:
- predictive intelligence systems.
Why This Matters for Autonomous AI
Autonomous AI systems need:
- prioritization
- relevance ranking
- signal extraction
Without ranking systems:
- everything becomes noise.
Trend engines help AI systems determine:
- what deserves attention.
What Comes Next
The next infrastructure layers will introduce:
- autonomous content generation
- AI-driven publishing
- semantic retrieval systems
- memory architectures
- observability dashboards
- multi-agent coordination
The platform is gradually evolving into:
- an operational AI intelligence platform.
Final Thoughts
Trend ranking engines are one of the most important components inside autonomous AI media systems.
They enable platforms to:
- identify emerging topics
- rank importance
- detect momentum
- extract meaningful signals from massive information streams
By combining:
- embeddings
- pgvector
- clustering
- recency weighting
- semantic intelligence
AgenticMediaLab now begins transitioning from:
- workflow orchestration
into:
- autonomous information intelligence.
