At this stage, AgenticMediaLab is evolving beyond:
- simple ingestion
- orchestration
- queue systems
and into:
- semantic intelligence.
Because autonomous AI systems do not merely process text.
They increasingly need to:
- understand similarity
- cluster information
- detect emerging themes
- search semantically
- compare meaning instead of keywords
This is where embeddings become one of the most important architectural layers in modern AI systems.
In this article, we will:
- generate embeddings
- store them inside PostgreSQL
- use pgvector
- prepare the platform for semantic search and trend detection
This is the beginning of the platform’s semantic memory layer.
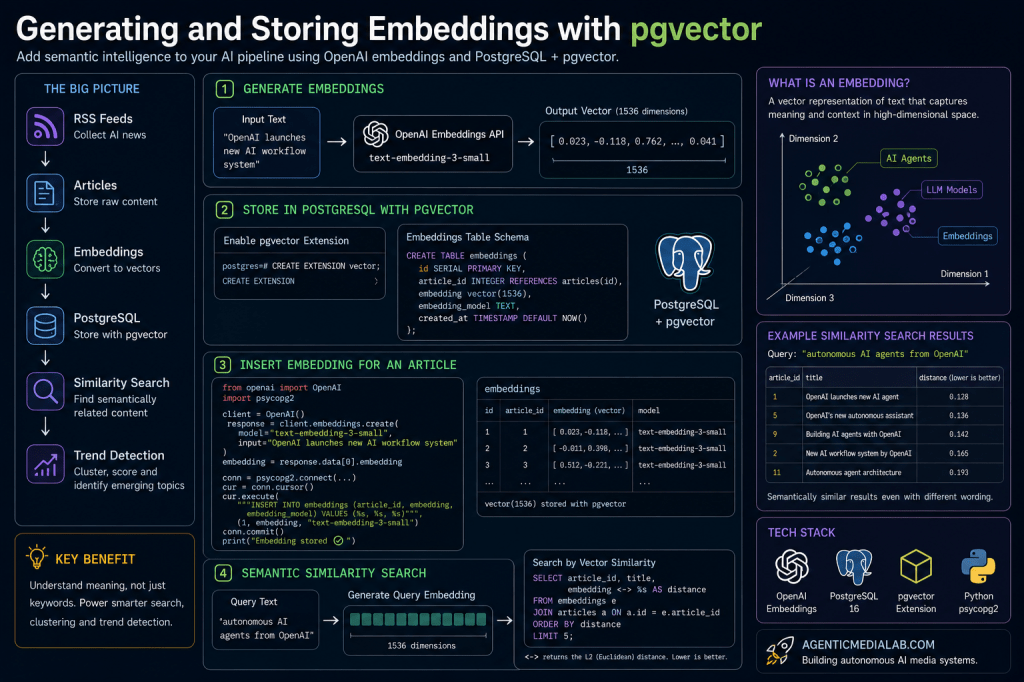
What Are Embeddings?
Embeddings are numerical vector representations of text.
Instead of storing content as:
- plain language
AI systems transform text into:
- high-dimensional vectors
These vectors capture:
- semantic meaning
- contextual similarity
- conceptual relationships
This enables systems to understand:
- meaning
instead of: - exact words.
Example Concept
These two headlines:
OpenAI launches new AI agent
and:
New autonomous assistant released by OpenAI
use different wording.
But embeddings place them:
- close together
inside vector space.
This enables:
- semantic search
- clustering
- trend analysis
- similarity ranking
Why Embeddings Matter for AI Media Systems
AgenticMediaLab eventually needs to:
- detect similar news stories
- identify trends
- cluster topics
- avoid duplicate summaries
- rank semantic relevance
Keyword matching alone is insufficient.
Embeddings provide the semantic intelligence layer.
Why pgvector?
Traditionally, vector search required:
But PostgreSQL now supports vectors directly through:
pgvector
This allows PostgreSQL to become:
- relational database
- vector database
- operational memory layer
inside one infrastructure stack.
Installing pgvector
If using Docker, update PostgreSQL image:
image: pgvector/pgvector:pg16
Then restart:
docker compose downdocker compose up
Enabling the Extension
Connect to PostgreSQL:
psql -U postgres -d agentic_media_lab
Enable pgvector:
CREATE EXTENSION vector;
Now PostgreSQL supports vector storage.
Updating the Repository Structure
Create:
embeddings/│├── generate_embeddings.py├── store_embeddings.py└── similarity_search.py
This becomes the semantic intelligence layer.
Installing OpenAI SDK
Install:
pip install openai
Generating the First Embedding
Create:
embeddings/generate_embeddings.py
Example:
from openai import OpenAIclient = OpenAI()response = client.embeddings.create( model="text-embedding-3-small", input="OpenAI launches new AI workflow system")embedding = response.data[0].embeddingprint(len(embedding))
Example output:
1536
The text has now been transformed into a semantic vector.
Why Vector Dimensions Matter
Embeddings are arrays of floating-point numbers.
Example:
[0.023, -0.118, 0.762, ...]
The dimensionality captures:
- semantic relationships
- contextual positioning
- conceptual similarity
Higher dimensions allow richer representations.
Creating the Embeddings Table
Update PostgreSQL schema:
CREATE TABLE embeddings ( id SERIAL PRIMARY KEY, article_id INTEGER REFERENCES articles(id), embedding vector(1536), embedding_model TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
This becomes the semantic storage layer.
Why vector(1536)?
Because:
text-embedding-3-small
returns:- 1536-dimensional vectors
The schema must match the embedding dimensions exactly.
Storing the Embedding
Create:
embeddings/store_embeddings.py
Example:
import psycopg2from openai import OpenAIclient = OpenAI()connection = psycopg2.connect( host="localhost", database="agentic_media_lab", user="postgres", password="password")cursor = connection.cursor()response = client.embeddings.create( model="text-embedding-3-small", input="OpenAI launches new AI workflow system")embedding = response.data[0].embeddingquery = """INSERT INTO embeddings ( article_id, embedding, embedding_model)VALUES (%s, %s, %s)"""cursor.execute(query, ( 1, embedding, "text-embedding-3-small"))connection.commit()print("Embedding stored")
What Just Happened?
The workflow now:
- generates semantic vectors
- stores them inside PostgreSQL
- links them to articles
The database is evolving into:
- semantic infrastructure.
Why Semantic Search Matters
Traditional search:
keyword → match
Semantic search:
meaning → similarity
This dramatically improves:
- relevance
- clustering
- recommendation systems
- trend detection
Running Similarity Search
Example query:
SELECT article_id, embedding <-> '[...]' AS distanceFROM embeddingsORDER BY distanceLIMIT 5;
The <-> operator performs:
- vector similarity comparison
Lower distance means:
- higher semantic similarity.
What This Enables
The platform can now:
- find related stories
- detect emerging themes
- group similar discussions
- identify topic clusters
- avoid duplicate content
This is foundational for autonomous media intelligence.
Example Future Workflow
The architecture is evolving toward:
RSS Feeds ↓Summarization ↓Embeddings ↓Similarity Search ↓Trend Clustering ↓Autonomous Publishing
This is no longer a simple content pipeline.
It is becoming:
- a semantic intelligence system.
Why Embeddings Change Everything
Embeddings fundamentally shift AI systems from:
- lexical processing
to:
- semantic understanding.
This transition is one of the most important ideas in modern AI infrastructure.
Common Beginner Mistake
Many developers initially use:
- keyword matching
- manual tagging
- categories
But semantic systems increasingly rely on:
- embeddings
- vector similarity
- clustering
- semantic retrieval
The architecture changes completely.
Why PostgreSQL + pgvector Is Powerful
Using PostgreSQL for:
- relational data
AND - vector search
simplifies infrastructure significantly.
Instead of managing:
- multiple databases
the platform can centralize:
- metadata
- embeddings
- operational workflows
- analytics
inside one system.
Observability for Embeddings
Embedding pipelines should track:
- generation latency
- token usage
- vector dimensions
- failure rates
- storage growth
Observability becomes increasingly important as vector workloads scale.
The Future — Semantic Trend Detection
Soon the system will evolve toward:
- topic clustering
- semantic ranking
- duplicate detection
- trend emergence analysis
This is where embeddings become operational intelligence.
Why This Is a Major Milestone
This article marks a major architectural shift.
The platform is now moving beyond:
- ingestion pipelines
and into:
- semantic AI infrastructure.
The system can now:
- understand relationships
- compare meaning
- analyze context
instead of simply processing text.
What Comes Next
The next infrastructure layers will introduce:
- clustering algorithms
- semantic trend detection
- retrieval workflows
- memory systems
- autonomous reasoning pipelines
The platform is gradually evolving into:
- a true autonomous AI system.
Final Thoughts
Embeddings are one of the foundational technologies behind modern AI systems.
They enable:
- semantic understanding
- similarity search
- contextual intelligence
- autonomous information analysis
By combining:
- OpenAI embeddings
- PostgreSQL
- pgvector
AgenticMediaLab now gains its first real semantic memory layer.
This is where the platform begins transitioning from:
- workflow automation
into:
- intelligent autonomous infrastructure.
