As autonomous AI systems grow more complex, one architectural problem appears very quickly:
Long-running tasks block the entire application.
For example:
- collecting RSS feeds
- generating embeddings
- summarizing articles
- calling LLM APIs
- detecting trends
- publishing content
can all take:
- seconds
- minutes
- or even longer
If these workflows run synchronously, the entire system becomes:
- slow
- fragile
- difficult to scale
This is where asynchronous task queues become essential.
At AgenticMediaLab, we are now introducing:
- Celery
- Redis
- distributed task execution
to transform the platform from:
- sequential scripts
into:
- operational AI infrastructure.
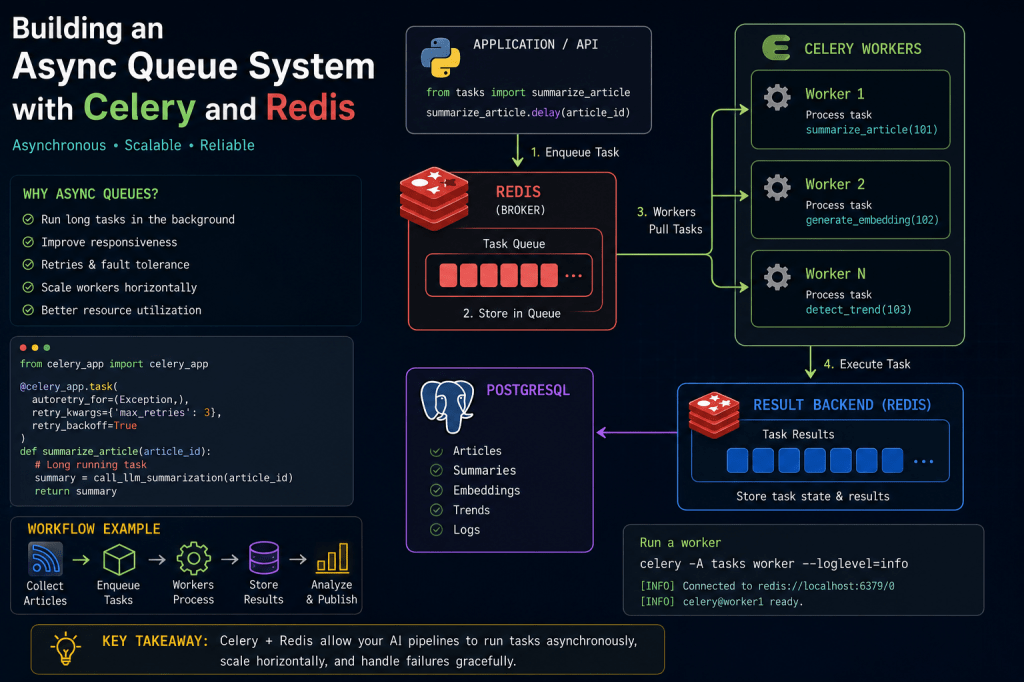
Why AI Systems Need Queues
Most beginner AI projects look like this:
Run Script ↓Wait ↓LLM Call ↓Wait ↓Store Result
This works initially.
But production systems require:
- parallel execution
- retries
- distributed processing
- background workers
- scheduling
- resilience
Without queues:
- workflows block each other
- failures cascade
- scaling becomes impossible
Queues become the backbone of autonomous systems.
High-Level Queue Architecture
The new infrastructure layer looks like this:
RSS Collector ↓Redis Queue ↓Celery Workers ↓AI Workflows ↓PostgreSQL
This separates:
- ingestion
- orchestration
- execution
- persistence
into independent operational layers.
Why Redis?
Redis acts as:
- the message broker
- queue backend
- task coordinator
It is:
- fast
- lightweight
- simple
- reliable
Redis is commonly used for:
- queues
- caching
- distributed coordination
- workflow state
inside modern AI infrastructure.
Why Celery?
Celery provides:
- distributed task execution
- background workers
- retries
- scheduling
- async processing
It allows workflows to execute independently from the main application.
This becomes critical for:
- LLM workloads
- embeddings
- ingestion systems
- AI pipelines
Installing Dependencies
Install Celery and Redis support:
pip install celery redis
Confirm Redis Is Running
If using Docker:
docker compose up
Check containers:
docker ps
You should see:
- PostgreSQL
- Redis
running successfully.
Updating the Repository Structure
New structure:
agentic-media-lab/│├── queues/│ ├── celery_app.py│ ├── tasks.py│ └── worker.py
This becomes the async execution layer.
Creating the Celery App
Create:
queues/celery_app.py
Example:
from celery import Celerycelery_app = Celery( "agentic_media_lab", broker="redis://localhost:6379/0", backend="redis://localhost:6379/0")
Understanding Broker vs Backend
Broker
Handles task distribution.
Example:
- Redis
Backend
Stores:
- task results
- completion state
- execution metadata
Redis can handle both initially.
Creating the First Async Task
Create:
queues/tasks.py
Example:
from celery_app import celery_appcelery_app.taskdef summarize_article(title): print(f"Summarizing: {title}") return f"Summary created for: {title}"
This is the first distributed workflow task.
Why Tasks Matter
Tasks become the operational units of execution.
Each workflow step becomes:
- isolated
- retryable
- scalable
- observable
This is the beginning of distributed AI infrastructure.
Running the Celery Worker
Start the worker:
celery -A queues.tasks worker --loglevel=info
If successful:
ready
appears in the console.
The worker is now listening for jobs.
Sending the First Task
Create:
queues/worker.py
Example:
from tasks import summarize_articleresult = summarize_article.delay( "New AI Model Released")print(result.id)
Run:
python queues/worker.py
What Just Happened?
Instead of executing directly:
Python Script ↓Immediate Execution
the task becomes:
Python Script ↓Redis Queue ↓Celery Worker ↓Execution
This is asynchronous infrastructure.
Why Async Execution Matters
Imagine:
- collecting 500 RSS articles
- generating embeddings
- summarizing content
- ranking trends
Sequential execution becomes extremely slow.
Queues enable:
- parallel processing
- distributed execution
- horizontal scaling
This is foundational for AI pipelines.
Adding Logging
Inside tasks.py:
import logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)
Example usage:
logger.info(f"Processing article: {title}")
Observability should begin immediately.
Adding Retry Logic
Real AI systems fail constantly.
Examples:
- API timeouts
- malformed outputs
- rate limits
- network failures
Celery supports retries.
Retry Example
celery_app.task( autoretry_for=(Exception,), retry_kwargs={"max_retries": 3}, retry_backoff=True)def summarize_article(title): print(f"Summarizing: {title}") return f"Summary created for: {title}"
Why Retries Matter
Retries are essential for:
- reliability
- resilience
- operational stability
Without retries:
- workflows collapse easily
- transient failures break pipelines
Operational AI systems must assume failure will happen.
Example AI Workflow Architecture
The system is gradually evolving into:
RSS Feeds ↓Collectors ↓Redis Queue ↓Celery Workers ↓LLM Summarization ↓PostgreSQL ↓Trend Detection
This is beginning to resemble a real AI platform.
Scaling Workers
One major advantage of Celery:
Workers scale horizontally.
Example:
Worker 1Worker 2Worker 3Worker 4
Each worker processes tasks independently.
This dramatically improves throughput.
Why Distributed Systems Matter
As AI workflows grow:
- token usage increases
- processing time increases
- orchestration complexity increases
Distributed execution becomes mandatory.
This is where AI engineering starts overlapping heavily with:
- platform engineering
- infrastructure engineering
- distributed systems
Adding Scheduled Tasks
Eventually we will add:
- recurring ingestion
- automated summarization
- scheduled publishing
Celery Beat can handle scheduling.
Example future workflow:
Every 5 Minutes ↓Collect AI News ↓Queue Tasks ↓Workers Process Data
This creates continuously operating pipelines.
Why Queues Are a Turning Point
This article marks a major architectural shift.
Before:
- scripts
- sequential execution
- local workflows
Now:
- distributed execution
- async processing
- scalable orchestration
The platform is evolving from:
- experimentation
into:
- infrastructure.
Common Beginner Mistake
Many developers initially build AI systems like this:
API Route ↓Run Everything ↓Wait 45 Seconds
This creates:
- blocking systems
- unstable applications
- scaling bottlenecks
Queues solve this problem.
Operational Benefits of Queues
Celery + Redis provide:
- async execution
- retries
- scalability
- fault tolerance
- distributed processing
- operational resilience
These are core infrastructure capabilities.
What Comes Next
The next infrastructure layers will introduce:
- LangGraph orchestration
- embeddings
- pgvector
- trend scoring
- publishing systems
- observability dashboards
The system is gradually becoming:
- autonomous
- distributed
- operational
Final Thoughts
Queues are one of the most important architectural layers in modern AI systems.
They transform:
- scripts
into:
- scalable workflows
and:
- isolated execution
into:
- operational infrastructure.
At AgenticMediaLab, Celery and Redis now become the foundation for:
- async processing
- distributed workflows
- autonomous orchestration
- resilient AI execution
This is where the platform truly begins evolving into a real autonomous AI system.
