One of the biggest differences between AI demos and real AI systems is structure.
Many AI projects begin as:
- notebooks
- isolated scripts
- experimental prototypes
But autonomous AI systems quickly grow into:
- distributed workflows
- orchestrated pipelines
- background workers
- monitoring systems
- databases
- queues
- observability infrastructure
Without proper architecture, these systems become:
- difficult to debug
- hard to scale
- expensive to maintain
- operationally fragile
At AgenticMediaLab, we are intentionally designing the project as a production-oriented autonomous AI system from the beginning.
In this article, we will build the foundational project structure for the entire platform.
This becomes the infrastructure backbone for:
- ingestion pipelines
- LangGraph workflows
- trend detection agents
- social publishing systems
- observability tooling
- deployment infrastructure
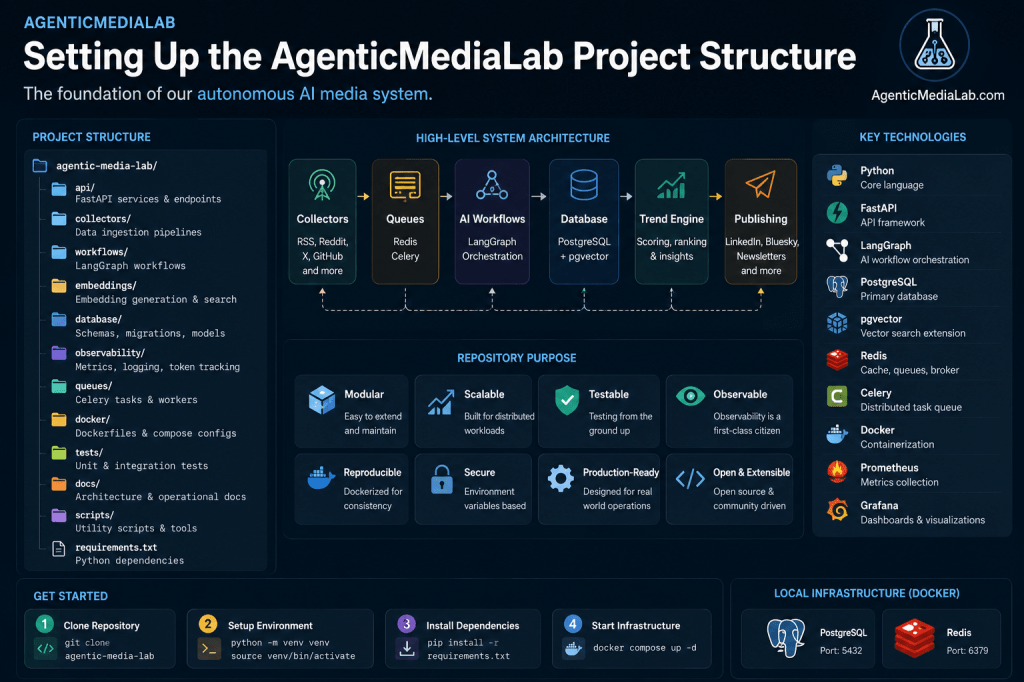
Why Project Structure Matters
Small AI demos can survive with:
- one file
- one prompt
- one API call
Production AI systems cannot.
As workflows grow, developers need:
- modular architecture
- environment separation
- reproducible deployments
- queue systems
- observability
- infrastructure isolation
A good structure reduces:
- engineering chaos
- technical debt
- operational failures
Project architecture is infrastructure engineering.
High-Level System Architecture
The long-term AgenticMediaLab architecture will look roughly like this:
Collectors ↓Queues ↓AI Workflows ↓Databases ↓Trend Detection ↓Publishing Pipelines ↓Observability
This architecture requires clear separation between components.
Choosing a Repository Strategy
There are generally two approaches:
Multi-Repository Architecture
Separate repositories for:
- collectors
- workflows
- dashboards
- APIs
Monorepo Architecture
One repository containing all services.
For AgenticMediaLab, we will start with a monorepo approach.
Why a Monorepo Works Well Initially
A monorepo simplifies:
- shared development
- architecture consistency
- dependency management
- deployment coordination
This is especially useful during:
- experimentation
- rapid iteration
- workflow redesigns
As systems grow larger, components can later split into separate repositories.
Initial Repository Structure
Our starting structure:
agentic-media-lab/│├── api/├── collectors/├── workflows/├── database/├── embeddings/├── observability/├── queues/├── docker/├── tests/├── docs/├── scripts/└── requirements.txt
Each directory serves a different operational purpose.
Folder Breakdown
/api
Contains:
- FastAPI services
- REST endpoints
- health checks
- workflow APIs
Example:
/api main.py routes/ services/
This becomes the external interface layer of the system.
/collectors
Handles ingestion systems.
Examples:
- RSS collectors
- Reddit collectors
- X/Twitter scrapers
- GitHub ingestion
Example:
/collectors /rss /reddit /github
Collectors feed data into downstream workflows.
/workflows
Contains orchestration logic.
Examples:
- LangGraph workflows
- summarization pipelines
- validation systems
- publishing workflows
Example:
/workflows summarization.py trend_detection.py
This becomes the operational AI layer.
/database
Contains:
- SQL schemas
- migrations
- ORM models
- database initialization scripts
Example:
/database schema.sql migrations/ models/
This layer stores:
- articles
- summaries
- embeddings
- metrics
- workflow states
/embeddings
Dedicated vector processing layer.
Examples:
- embedding generation
- similarity search
- clustering utilities
- semantic ranking
Example:
/embeddings generate_embeddings.py similarity_search.py
This powers semantic intelligence throughout the platform.
/observability
One of the most important production layers.
Contains:
- token tracking
- metrics
- tracing
- logging
- workflow monitoring
Example:
/observability metrics.py token_logger.py
Observability is critical in autonomous AI systems.
/queues
Handles distributed workflow execution.
Examples:
- Celery workers
- Redis integration
- retry systems
- async orchestration
Example:
/queues celery_worker.py tasks.py
Queues enable scalable processing.
/docker
Contains deployment infrastructure.
Examples:
- Dockerfiles
- Docker Compose
- container configs
Example:
/docker Dockerfile.api Dockerfile.worker docker-compose.yml
Containerization improves:
- reproducibility
- deployment consistency
- scaling
/tests
Production systems require testing.
Examples:
- unit tests
- workflow tests
- validation tests
- integration tests
Example:
/tests test_collectors.py test_workflows.py
Testing becomes increasingly important as workflows scale.
/docs
Stores:
- architecture diagrams
- operational notes
- workflow documentation
- infrastructure discussions
Example:
/docs architecture.md deployment_notes.md
Documentation becomes part of the engineering system itself.
Setting Up the Python Environment
Create the repository:
mkdir agentic-media-labcd agentic-media-lab
Create Virtual Environment
python -m venv venv
Activate environment:
Linux/macOS:
source venv/bin/activate
Windows:
venv\Scripts\activate
Installing Initial Dependencies
Initial stack:
pip install fastapi uvicorn openai langgraph pydantic
Additional infrastructure:
pip install celery redis sqlalchemy psycopg2-binary
Save dependencies:
pip freeze > requirements.txt
Why Dependency Discipline Matters
AI projects often become dependency chaos.
Good practices:
- pin versions
- isolate environments
- document dependencies
- avoid unnecessary libraries
This reduces deployment instability.
Creating the First FastAPI App
Inside /api/main.py:
from fastapi import FastAPIapp = FastAPI()app.get("/")def root(): return { "message": "AgenticMediaLab API running" }
Run server:
uvicorn api.main:app --reload
Open:
http://127.0.0.1:8000
This becomes the first operational service.
Environment Variables
Never hardcode:
- API keys
- passwords
- database credentials
Create .env:
OPENAI_API_KEY=your_key_herePOSTGRES_HOST=localhostPOSTGRES_DB=agentic_media_labPOSTGRES_USER=postgresPOSTGRES_PASSWORD=passwordREDIS_HOST=localhost
Why Environment Separation Matters
Different environments require different settings:
Development
Local experimentation.
Staging
Pre-production testing.
Production
Operational deployment.
Environment isolation reduces deployment risk.
Initial Docker Setup
Create docker-compose.yml:
version: '3'services: postgres: image: postgres:16 environment: POSTGRES_DB: agentic_media_lab POSTGRES_USER: postgres POSTGRES_PASSWORD: password ports: - "5432:5432" redis: image: redis:7 ports: - "6379:6379"
Run:
docker compose up
Now the system has:
- PostgreSQL
- Redis
- local infrastructure services
This is the beginning of operational architecture.
Why Redis Matters
Redis powers:
- queues
- caching
- retries
- workflow coordination
- distributed state
It becomes foundational for autonomous systems.
Why PostgreSQL Matters
PostgreSQL stores:
- articles
- summaries
- embeddings
- workflows
- metrics
- token logs
Modern AI systems increasingly become database-centric systems.
Logging Setup
Create basic logger:
import logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)
Logging becomes essential for:
- debugging
- observability
- operational analysis
The Importance of Observability Early
Many developers postpone monitoring.
This is a mistake.
Even early prototypes should track:
- workflow failures
- token usage
- retries
- execution time
Observability should begin immediately.
Recommended Early Development Workflow
Step 1
Collectors ingest data.
Step 2
Data stored in PostgreSQL.
Step 3
Queues process workflows.
Step 4
LangGraph orchestrates pipelines.
Step 5
Observability tracks operations.
This architecture scales naturally over time.
What Comes Next
With the foundational structure complete, the next articles will begin implementing real systems:
- RSS ingestion
- PostgreSQL schemas
- async queues
- LangGraph workflows
- embeddings
- trend ranking
- publishing systems
The platform will gradually evolve into a continuously operating autonomous AI media infrastructure system.
Why This Structure Is Important
The goal is not simply:
- generating AI outputs
The goal is:
- engineering operational AI systems
That requires:
- architecture
- orchestration
- observability
- infrastructure discipline
This project structure creates the foundation for everything that follows.
Final Thoughts
Most AI tutorials stop at:
- prompts
- demos
- isolated scripts
Real AI systems require:
- workflow engineering
- deployment infrastructure
- queues
- databases
- observability
- reliability systems
Project structure is the first step toward building those systems correctly.
At AgenticMediaLab, we are intentionally building:
- modular workflows
- scalable infrastructure
- autonomous orchestration systems
in public and step by step.
This is where AI applications begin evolving into real operational systems.
👉 You can experiment with a practical AI News System implementation of this concept in the official GitHub repository for the AgenticMediaLab: https://github.com/BenardoKemp/agentic-media-lab
