One of the biggest misconceptions about AI systems is that the difficult part is generating outputs.
In reality, the difficult part is surviving failures.
Autonomous AI systems operate in unstable environments:
- APIs fail
- prompts break
- models hallucinate
- queues back up
- workflows loop unexpectedly
- scraping pipelines collapse
- retries multiply costs
- malformed outputs corrupt downstream systems
The more autonomous a system becomes, the more important failure recovery becomes.
This is especially true in:
- AI media systems
- orchestration pipelines
- multi-agent architectures
- long-running workflows
- autonomous publishing systems
At AgenticMediaLab, failure recovery is treated as a foundational infrastructure layer rather than an optional feature.
In this article, we will explore how modern AI systems recover from failures and how to engineer more resilient autonomous pipelines.
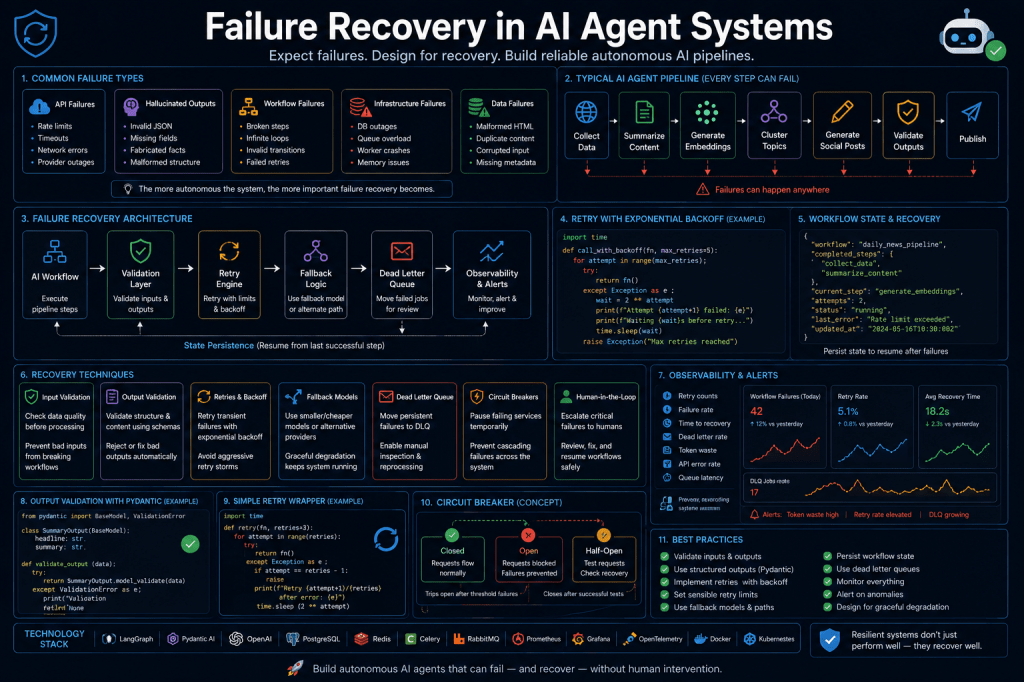
Why Failure Recovery Matters
Simple demos rarely show failures.
Production systems experience failures continuously.
A typical autonomous AI workflow may involve:
Collect Data ↓Summarize Content ↓Generate Embeddings ↓Cluster Topics ↓Generate Social Posts ↓Validate Outputs ↓Publish
Every stage can fail independently.
Without recovery systems:
- workflows crash
- queues freeze
- costs explode
- outputs become unreliable
Reliability engineering becomes one of the most important disciplines in agentic AI systems.
Common Failure Types in AI Pipelines
AI systems fail differently than traditional software systems.
They introduce probabilistic failures.
1. API Failures
Examples:
- rate limits
- network errors
- provider outages
- timeout failures
2. Hallucinated Outputs
Examples:
- invalid JSON
- fabricated facts
- malformed structures
- missing fields
3. Workflow Failures
Examples:
- broken orchestration paths
- infinite loops
- invalid state transitions
- failed retries
4. Infrastructure Failures
Examples:
- database outages
- queue overloads
- worker crashes
- memory exhaustion
5. Data Failures
Examples:
- malformed HTML
- duplicate content
- corrupted input
- missing metadata
Autonomous systems must expect failure continuously.
The Shift from Prompt Engineering to Reliability Engineering
Most beginner AI tutorials focus on:
- prompts
- model selection
- output quality
Production systems focus on:
- retries
- observability
- validation
- orchestration
- fault tolerance
- graceful degradation
This is a major transition in AI engineering.
High-Level Recovery Architecture
A resilient AI system often includes:
AI Workflow ↓Validation Layer ↓Retry Engine ↓Fallback Logic ↓Dead Letter Queue ↓Observability & Alerts
Each layer contributes to operational resilience.
Step 1 — Input Validation
Recovery begins before the AI model executes.
Bad inputs create unstable outputs.
Example Validation
def validate_input(text): if not text: return False if len(text) < 20: return False return True
Validation prevents:
- wasted tokens
- malformed prompts
- unstable workflows
Why Validation Matters
Autonomous systems ingest noisy internet data.
Without filtering:
- prompts become inconsistent
- hallucinations increase
- retries multiply
- costs grow rapidly
Validation is defensive infrastructure.
Step 2 — Output Validation
LLM outputs should never be trusted blindly.
Even high-quality models produce:
- malformed JSON
- missing fields
- invalid structures
- hallucinated content
Example Structured Output Validation
from pydantic import BaseModelclass SummaryOutput(BaseModel): headline: str summary: str
Validation Example
try: result = SummaryOutput.model_validate(data)except Exception: print("Validation failed")
Structured validation is one of the most important production patterns in AI systems.
Step 3 — Retry Systems
Retries are essential in distributed AI architectures.
But retries must be controlled carefully.
Simple Retry Example
import timedef retry(fn, retries=3): for attempt in range(retries): try: return fn() except Exception: print(f"Retry {attempt + 1}") time.sleep(2) raise Exception("Workflow failed")
Why Retries Are Dangerous
Poor retry systems can create:
- retry storms
- token explosions
- queue overloads
- duplicate publishing
- cascading failures
Recovery systems must include limits and observability.
Step 4 — Exponential Backoff
Production systems often use exponential backoff.
This reduces pressure on overloaded services.
Example Backoff Strategy
import timefor attempt in range(5): try: result = call_api() break except Exception: wait_time = 2 ** attempt print(f"Waiting {wait_time} seconds") time.sleep(wait_time)
This prevents aggressive retry loops.
Step 5 — Fallback Models
Not every workflow requires the largest model.
When failures occur, systems may:
- downgrade models
- simplify prompts
- reduce context size
Example Fallback Logic
try: model = "gpt-4.1" result = generate(model)except Exception: model = "gpt-4.1-mini" result = generate(model)
Fallback systems improve resilience significantly.
Step 6 — Dead Letter Queues
Some workflows should not retry forever.
Persistent failures should move into:
- review queues
- quarantine systems
- dead letter queues
Dead Letter Queue Concept
Workflow Failure ↓Max Retry Reached ↓Dead Letter Queue ↓Manual Inspection
This prevents runaway workflows.
Why Dead Letter Queues Matter
Without them:
- failed jobs loop endlessly
- costs escalate
- systems become unstable
Dead letter queues are foundational in distributed systems engineering.
Step 7 — State Recovery
Long-running workflows require state persistence.
Without state recovery:
- crashes lose progress
- expensive tasks repeat
- workflows restart unnecessarily
Example Workflow State
state = { "completed_steps": [ "ingestion", "summarization" ]}
State recovery enables:
- resumable execution
- partial recovery
- operational continuity
Step 8 — Circuit Breakers
Circuit breakers temporarily disable failing systems.
Example:
- API provider outage
- database instability
- overloaded queue systems
Circuit Breaker Workflow
Failure Spike ↓Circuit Opens ↓Requests Paused ↓Recovery Check ↓Circuit Closes
This prevents cascading failures.
Step 9 — Human-in-the-Loop Recovery
Not every failure should be automated.
Critical workflows often require:
- human review
- approval systems
- escalation paths
Example Human Recovery Flow
Workflow Failure ↓Escalation Queue ↓Human Review ↓Resume Workflow
This is especially important for:
- publishing systems
- enterprise workflows
- compliance pipelines
Step 10 — Observability
Recovery systems require visibility.
Without observability:
- failures remain hidden
- debugging becomes impossible
- optimization becomes difficult
Important Metrics
Production systems track:
- retry counts
- failed workflows
- token waste
- queue latency
- API errors
- timeout rates
- validation failures
Example Monitoring Metrics
{ "workflow_failures": 42, "retry_rate": 5.1, "average_recovery_time": 18.2}
Observability transforms failures into engineering insights.
Why LangGraph Helps Recovery
LangGraph is particularly useful because workflows are:
- stateful
- structured
- graph-oriented
This makes recovery easier.
Each node can:
- retry independently
- persist state
- branch conditionally
- resume execution
Example LangGraph Recovery Flow
Summarization Failure ↓Retry Node ↓Fallback Model ↓Validation ↓Continue Workflow
Graph orchestration creates more resilient systems.
Recommended Production Stack
A resilient AI infrastructure stack may include:
Orchestration
- LangGraph
- Celery
- Temporal
Validation
- Pydantic AI
- schema validators
Monitoring
- Prometheus
- Grafana
- OpenTelemetry
Storage
- PostgreSQL
- Redis
Queues
- RabbitMQ
- Redis queues
- Kafka
Deployment
- Docker
- Kubernetes
Autonomous AI systems increasingly resemble distributed cloud infrastructure.
Common Reliability Mistakes
Infinite Retry Loops
Retries without limits.
Blind Trust in LLM Outputs
Skipping validation entirely.
Missing Observability
No metrics or tracing.
No State Persistence
Long workflows restart unnecessarily.
Aggressive Automation
Publishing without safeguards.
Retry Storms
Failures triggering massive cascading retries.
These mistakes become extremely expensive at scale.
The Reality of Autonomous Systems
The more autonomous a system becomes:
- the more failures it encounters
- the more resilience it requires
Agentic systems are fundamentally operational systems.
This means:
- observability matters
- orchestration matters
- fault tolerance matters
- infrastructure matters
AI engineering increasingly overlaps with distributed systems engineering.
Final Thoughts
Failure recovery is one of the most important aspects of autonomous AI systems.
Reliable AI pipelines require:
- validation
- retries
- state recovery
- fallback systems
- observability
- human escalation
- fault isolation
By combining:
- orchestration frameworks
- structured validation
- resilient infrastructure
- operational monitoring
developers can build AI systems capable of surviving real-world instability at scale.
The future of AI engineering is not only about:
- smarter models
It is also about:
- resilient systems
- operational discipline
- recovery architecture
- infrastructure reliability
This is where AI applications evolve into production-grade autonomous systems.
👉 You can experiment with a practical AI News System implementation of this concept in the official GitHub repository for the AgenticMediaLab: https://github.com/BenardoKemp/agentic-media-lab
