Every autonomous AI media system starts with one critical capability:
Reliable information ingestion.
Before an AI agent can summarize trends, generate newsletters, or publish content automatically, it first needs a way to continuously collect information from external sources.
This process is often called ingestion.
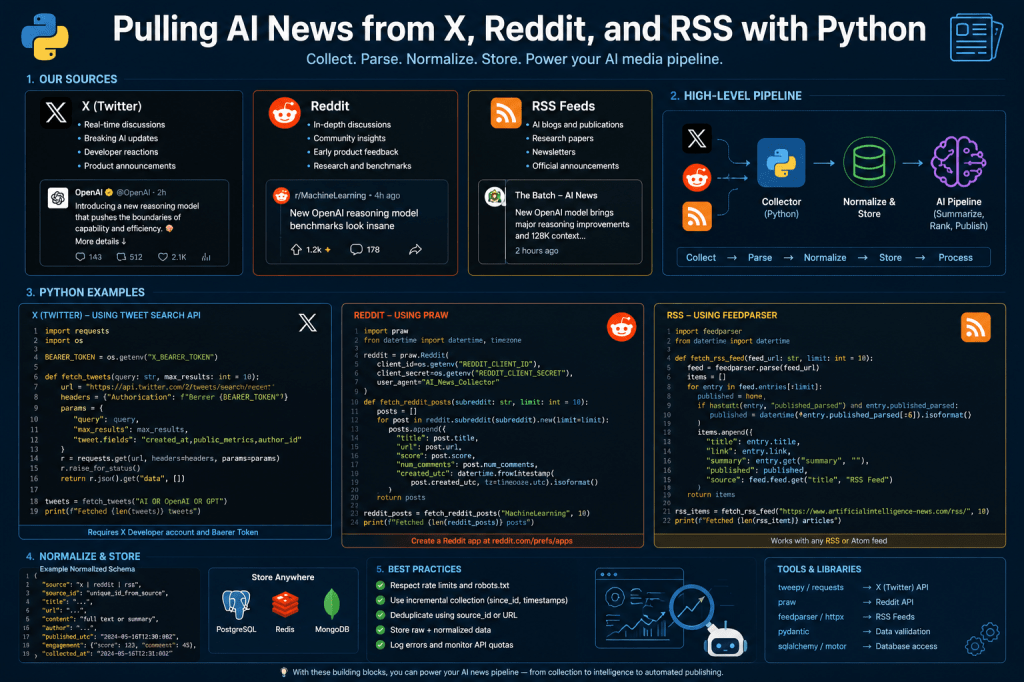
In this article, we will build the foundation of an AI news ingestion pipeline using Python. We will explore how to collect AI-related information from:
- X/Twitter
- RSS feeds
and normalize that data into a structured format that can later be processed by AI workflows.
This is the first practical engineering layer behind an autonomous AI media system.
Why Ingestion Matters
Most AI tutorials begin with prompts.
Production systems begin with data pipelines.
Without a reliable ingestion layer:
- summaries become outdated
- trend detection fails
- agents hallucinate context
- automation pipelines break
- AI systems lose relevance
The ingestion layer determines:
- what your AI system knows
- how quickly it reacts
- how much noise enters the pipeline
- how expensive downstream processing becomes
In many cases, ingestion quality matters more than model selection.
Architecture Overview
Our ingestion system will follow a simple architecture:
X / Reddit / RSS ↓Collectors & Crawlers ↓Normalization Layer ↓Structured JSON Records ↓Database / Queue / AI Pipeline
The goal is not just to scrape content.
The goal is to transform multiple inconsistent sources into a unified data format that downstream AI systems can process reliably.
Recommended Python Libraries
We will use a lightweight but production-friendly stack.
RSS Parsing
feedparser
HTTP Requests
requests
HTML Parsing
beautifulsoup4
Browser Automation
playwright
Data Validation
pydantic
Install everything:
pip install feedparser requests beautifulsoup4 playwright pydantic
Then install Playwright browsers:
playwright install
Step 1 — Pulling AI News from RSS Feeds
RSS remains one of the cleanest ways to ingest news content.
Many AI blogs and news websites still publish RSS feeds.
Example AI RSS Sources
Some example feeds:
- OpenAI Blog
- Anthropic News
- Hugging Face Blog
- VentureBeat AI
- The Batch by DeepLearning.AI
Basic RSS Reader
import feedparserRSS_FEEDS = [ "https://openai.com/blog/rss.xml", "https://huggingface.co/blog/feed.xml"]def fetch_rss_articles(): articles = [] for feed_url in RSS_FEEDS: feed = feedparser.parse(feed_url) for entry in feed.entries: articles.append({ "source": feed.feed.title, "title": entry.title, "link": entry.link, "published": entry.get("published", ""), "summary": entry.get("summary", "") }) return articlesarticles = fetch_rss_articles()for article in articles[:3]: print(article)
Why RSS Is Valuable
RSS ingestion has several advantages:
- stable structure
- lower scraping complexity
- fewer anti-bot protections
- cleaner metadata
- lower operational cost
However:
- not all websites expose RSS
- some feeds are delayed
- content depth may be limited
Most production systems combine RSS with scraping and APIs.
Step 2 — Pulling AI Discussions from Reddit
Reddit is one of the richest sources for AI discussions, experiments, releases, and developer reactions.
Relevant subreddits include:
- r/artificial
- r/MachineLearning
- r/LocalLLaMA
- r/OpenAI
- r/singularity
Using Reddit JSON Endpoints
Reddit exposes lightweight JSON endpoints.
Example:
https://www.reddit.com/r/artificial/new.json
Reddit Fetch Example
import requestsHEADERS = { "User-Agent": "AgenticMediaLabBot/1.0"}def fetch_reddit_posts(subreddit="artificial"): url = f"https://www.reddit.com/r/{subreddit}/new.json" response = requests.get(url, headers=HEADERS) data = response.json() posts = [] for item in data["data"]["children"]: post = item["data"] posts.append({ "source": f"reddit/{subreddit}", "title": post["title"], "author": post["author"], "url": post["url"], "score": post["score"], "comments": post["num_comments"] }) return postsposts = fetch_reddit_posts()for post in posts[:3]: print(post)
Important Reddit Considerations
Reddit ingestion introduces challenges:
- rate limits
- deleted content
- spam
- duplicate discussions
- inconsistent quality
Production pipelines often add:
- engagement thresholds
- language filtering
- duplicate clustering
- source scoring
before content reaches AI summarization systems.
Step 3 — Pulling AI Content from X/Twitter
X is significantly more difficult to ingest reliably.
Modern social platforms actively defend against scraping.
There are usually three approaches:
Option 1 — Official API
Most stable but limited and often expensive.
Option 2 — Third-Party APIs
Faster to implement but introduces external dependencies.
Option 3 — Browser Automation
Most flexible but operationally complex.
For educational purposes, browser automation provides the clearest understanding of the ingestion process.
Playwright Example
from playwright.sync_api import sync_playwrightdef fetch_x_posts(): posts = [] with sync_playwright() as p: browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto("https://twitter.com/search?q=AI&src=typed_query") page.wait_for_timeout(5000) tweets = page.locator("article").all() for tweet in tweets[:5]: text = tweet.inner_text() posts.append({ "source": "x", "content": text }) browser.close() return postsresults = fetch_x_posts()for post in results: print(post)
Why Social Media Ingestion Is Hard
Social platforms introduce many operational challenges:
- anti-bot systems
- login requirements
- DOM changes
- infinite scrolling
- rate limits
- dynamic rendering
- IP blocking
This is why many production AI pipelines rely on hybrid architectures:
- APIs where possible
- browser automation where necessary
- queues for retries
- proxy infrastructure
- caching systems
Ingestion engineering quickly becomes infrastructure engineering.
Step 4 — Normalizing the Data
Different sources produce inconsistent data structures.
AI systems require standardized inputs.
This normalization layer is one of the most important parts of the pipeline.
Pydantic Data Model
from pydantic import BaseModelfrom typing import Optionalclass NewsItem(BaseModel): source: str title: Optional[str] content: Optional[str] url: Optional[str] author: Optional[str] published: Optional[str]
Example Normalized Record
item = NewsItem( source="reddit/artificial", title="New Open Source AI Model Released", content="Discussion about the new release...", url="https://reddit.com/...", author="user123")print(item.model_dump())
Output:
{ "source": "reddit/artificial", "title": "New Open Source AI Model Released", "content": "Discussion about the new release...", "url": "https://reddit.com/...", "author": "user123", "published": null}
This standardization becomes essential for:
- AI summarization
- embeddings
- vector search
- ranking
- deduplication
- orchestration systems
Step 5 — Deduplication
One of the biggest ingestion problems is duplicate content.
The same AI release may appear:
- on Reddit
- on X
- on RSS feeds
- on YouTube
- across multiple blogs
Without deduplication:
- token costs increase
- summaries become repetitive
- trend detection becomes distorted
Simple Deduplication Example
seen_titles = set()unique_articles = []for article in articles: title = article["title"] if title not in seen_titles: seen_titles.add(title) unique_articles.append(article)
Production systems typically use:
- embeddings
- semantic similarity
- clustering algorithms
- fuzzy matching
for better duplicate detection.
Step 6 — Preparing for AI Processing
Once ingestion is complete, data is usually sent into:
- queues
- databases
- vector stores
- orchestration systems
Typical next steps include:
- summarization
- classification
- trend analysis
- ranking
- social post generation
This is where frameworks like:
- LangGraph
- Pydantic AI
- Celery
- FastAPI
begin to play larger roles.
Recommended Production Architecture
As systems grow, ingestion pipelines often evolve into this structure:
Collectors ↓Message Queue ↓Normalization Workers ↓Deduplication Layer ↓Database / Vector Store ↓AI Processing Pipeline ↓Publishing Systems
This architecture improves:
- scalability
- fault tolerance
- retry handling
- throughput
- observability
Common Ingestion Challenges
Anti-Bot Protection
Modern websites aggressively block automation.
Data Quality
Internet content is noisy and inconsistent.
Cost Management
Large-scale scraping can become expensive.
Scheduling
Some sources update continuously while others update slowly.
Reliability
External sources can disappear or change format unexpectedly.
Latency
Real-time pipelines require careful optimization.
These challenges are often underestimated in AI engineering discussions.
Final Thoughts
Ingestion is the foundation of every autonomous AI media system.
Without reliable data collection:
- AI reasoning becomes weak
- summaries become outdated
- trend detection fails
- automation loses value
The most powerful AI systems are not only built on models.
They are built on pipelines.
By combining:
- RSS ingestion
- Reddit collection
- browser automation
- normalization
- deduplication
you create the first layer of a real-world AI news architecture.
In future articles, we will build on this ingestion layer to create:
- AI summarization systems
- orchestration workflows
- autonomous publishing pipelines
- observability systems
- trend analysis agents
This is where isolated AI prompts evolve into operational AI systems.
👉 You can experiment with a practical AI News System implementation of this concept in the official GitHub repository for the AgenticMediaLab: https://github.com/BenardoKemp/agentic-media-lab
