Once an AI pipeline can reliably ingest information, the next major challenge begins:
Turning large amounts of noisy, fragmented content into concise and useful intelligence.
This is where AI summarization systems become essential.
A modern autonomous media pipeline may collect:
- RSS articles
- Reddit discussions
- X/Twitter posts
- YouTube transcripts
- GitHub updates
- blog posts
- API feeds
But raw information alone has limited value.
The real value comes from transforming scattered content into:
- readable summaries
- trend briefings
- research digests
- social media insights
- operational intelligence
In this article, we will explore how to build a multi-source AI summarization system using Python and modern AI workflows.
This is one of the core intelligence layers behind autonomous AI media systems.
Why Multi-Source Summarization Matters
Single-source summarization is relatively simple.
Multi-source summarization is significantly harder.
Why?
Because different sources often:
- overlap
- contradict each other
- contain partial information
- repeat the same events
- introduce noise
- vary in quality
For example:
- RSS feeds may contain formal announcements
- Reddit may contain developer reactions
- X may contain breaking discussions
- YouTube may contain deeper technical analysis
A good AI summarization system must combine these perspectives into a coherent output.
This is where orchestration and structured processing become critical.
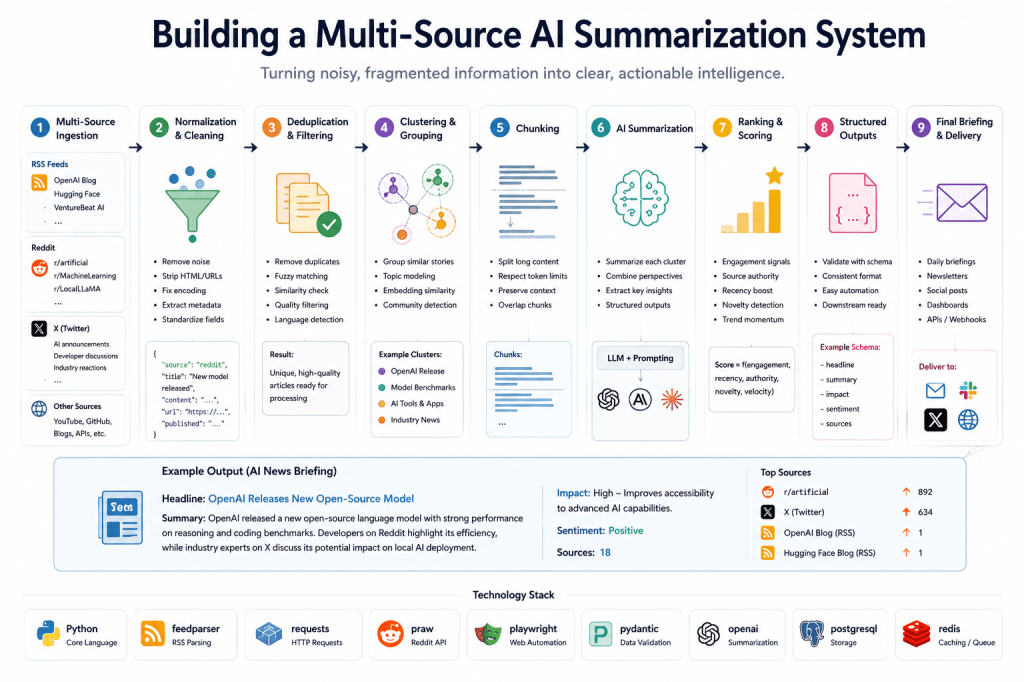
High-Level System Architecture
Our summarization pipeline will follow this structure:
Ingestion Sources ↓Normalization Layer ↓Deduplication Layer ↓Chunking & Grouping ↓AI Summarization ↓Ranking & Scoring ↓Final Briefing Output
Each stage solves a different engineering problem.
Step 1 — Defining a Unified Data Model
Before summarization begins, all sources should follow a consistent structure.
This allows downstream workflows to remain predictable.
Pydantic Data Model
from pydantic import BaseModelfrom typing import Optionalclass NewsItem(BaseModel): source: str title: Optional[str] content: Optional[str] url: Optional[str] author: Optional[str] published: Optional[str]
Example Input
item = NewsItem( source="reddit/artificial", title="New Open Source Model Released", content="Developers discuss benchmark results...", url="https://reddit.com/...")
This normalized format becomes essential for:
- chunking
- embeddings
- deduplication
- ranking
- orchestration workflows
Step 2 — Cleaning the Content
Raw internet data contains noise.
Common problems include:
- emojis
- URLs
- advertisements
- duplicate text
- malformed formatting
- tracking codes
Poor preprocessing produces poor summaries.
Simple Cleaning Function
import redef clean_text(text: str) -> str: text = re.sub(r"http\\S+", "", text) text = re.sub(r"\\s+", " ", text) return text.strip()
Why Cleaning Matters
LLMs are probabilistic systems.
The more irrelevant information included:
- the more tokens wasted
- the greater hallucination risk
- the lower summary quality
In large-scale pipelines, preprocessing quality heavily affects operational cost.
Step 3 — Deduplicating Similar Content
The same story often appears across multiple sources.
For example:
- OpenAI announcement via RSS
- Reddit discussion about the announcement
- X reactions
- blog reposts
Without deduplication:
- summaries become repetitive
- token costs increase
- rankings become distorted
Simple Title Deduplication
seen_titles = set()unique_items = []for item in news_items: if item.title not in seen_titles: seen_titles.add(item.title) unique_items.append(item)
Production-Grade Deduplication
Real systems often use:
- embeddings
- cosine similarity
- semantic clustering
- fuzzy matching
- vector databases
because duplicate titles alone are insufficient.
Step 4 — Grouping Related Stories
Once duplicates are removed, related stories should be grouped into topics.
This allows the AI to summarize clusters rather than isolated posts.
Example Topic Clusters
A cluster may contain:
- OpenAI release announcement
- Reddit benchmark discussion
- X reactions
- GitHub implementation updates
Grouping improves:
- coherence
- context
- summarization depth
- trend detection
Simple Grouping Example
from collections import defaultdictclusters = defaultdict(list)for item in unique_items: topic = "openai" if "OpenAI" in item.title else "other" clusters[topic].append(item)
Production systems typically use:
- embeddings
- topic modeling
- semantic similarity search
instead of keyword grouping.
Step 5 — Chunking Large Content
LLMs have context limits.
Long discussions or transcripts must be split into manageable chunks.
Basic Chunking Function
def chunk_text(text, chunk_size=1000): return [ text[i:i+chunk_size] for i in range(0, len(text), chunk_size) ]
Chunking becomes critical when processing:
- Reddit comment threads
- YouTube transcripts
- research articles
- long blog posts
Step 6 — Generating AI Summaries
Now the pipeline can begin actual AI summarization.
This is where:
- OpenAI models
- orchestration frameworks
- structured outputs
enter the architecture.
Basic OpenAI Summarization Example
from openai import OpenAIclient = OpenAI()def summarize_text(text): response = client.chat.completions.create( model="gpt-4.1-mini", messages=[ { "role": "system", "content": "You summarize AI news clearly and concisely." }, { "role": "user", "content": text } ] ) return response.choices[0].message.content
Why Prompt Design Matters
Prompt engineering becomes more important in multi-source summarization.
The model must:
- combine perspectives
- remove duplicates
- preserve factual accuracy
- identify the core event
- avoid speculation
A weak prompt often produces:
- generic summaries
- repetitive wording
- hallucinations
- missed insights
Example Multi-Source Prompt
PROMPT = """You are an AI news analyst.Summarize the following grouped AI discussions into:1. Main development2. Important technical details3. Community reaction4. Potential impactKeep the summary concise and factual."""
Step 7 — Structured Outputs
Unstructured summaries become difficult to automate downstream.
Structured outputs improve:
- reliability
- orchestration
- storage
- publishing
Pydantic Summary Schema
class SummaryOutput(BaseModel): headline: str summary: str impact: str sentiment: str
Why Structured Outputs Matter
Structured AI systems are easier to:
- validate
- retry
- monitor
- publish automatically
- feed into workflows
This is one reason frameworks like Pydantic AI are becoming increasingly important.
Step 8 — Ranking and Importance Scoring
Not every AI story deserves equal attention.
Production pipelines often rank content based on:
- engagement
- novelty
- source authority
- social velocity
- cluster size
- relevance
Example Scoring Logic
def calculate_score(post): return ( post.get("comments", 0) * 2 + post.get("score", 0) )
Advanced systems may use:
- embeddings
- trend momentum
- historical comparisons
- AI-generated scoring
Step 9 — Generating Final Briefings
After summarization and ranking, the pipeline can generate:
- newsletters
- social media posts
- daily briefings
- dashboards
- research reports
Example output:
Today’s Top AI Story:Open-source developers released a new high-performance language model benchmarked against several commercial systems. Reddit discussions focused heavily on inference efficiency and fine-tuning capabilities, while social media reactions highlighted its potential impact on local AI deployment.
This becomes the operational output of the pipeline.
Recommended Architecture Stack
A modern summarization pipeline might use:
AI Layer
- OpenAI SDK
- LangGraph
- Pydantic AI
Data Layer
- PostgreSQL
- Redis
- vector databases
Workflow Layer
- Celery
- queue systems
- async workers
Crawling Layer
- Playwright
- feedparser
- API collectors
Monitoring
- logging
- tracing
- token tracking
Common Challenges
Hallucinations
AI models may invent facts when combining sources.
Duplicate Summaries
Poor clustering leads to repetitive outputs.
Token Costs
Large-scale summarization becomes expensive quickly.
Source Bias
Different platforms emphasize different perspectives.
Latency
Complex workflows increase processing time.
Context Fragmentation
LLMs may miss relationships between disconnected pieces of information.
These challenges become more important as systems scale.
Why Orchestration Matters
Multi-source summarization is rarely a single LLM call.
Real pipelines often involve:
- ingestion
- preprocessing
- deduplication
- clustering
- summarization
- validation
- ranking
- publishing
This is why orchestration frameworks like LangGraph are increasingly valuable.
AI systems are becoming workflow systems.
Final Thoughts
A multi-source AI summarization system transforms fragmented internet discussions into usable intelligence.
By combining:
- ingestion pipelines
- normalization
- clustering
- AI summarization
- structured outputs
- ranking systems
you create the foundation for:
- AI news briefings
- autonomous research systems
- social media automation
- operational intelligence platforms
The future of AI media systems is not just collecting information.
It is understanding information at scale.
In future articles, we will build on this system to explore:
- orchestration workflows
- trend detection agents
- automated publishing systems
- observability pipelines
- autonomous content generation
This is where AI pipelines begin evolving into fully operational agentic systems.
👉 You can experiment with a practical AI News System implementation of this concept in the official GitHub repository for the AgenticMediaLab: https://github.com/BenardoKemp/agentic-media-lab
