Modern AI systems are rapidly evolving beyond simple chatbots and isolated prompt-response interactions.
One of the most practical and educational examples of this shift is the autonomous AI news pipeline: a system capable of collecting information from multiple sources, processing it with AI, generating summaries or content, and distributing the results automatically.
These systems combine:
- data ingestion
- orchestration
- AI reasoning
- workflow automation
- scheduling
- observability
- publishing infrastructure
In other words, they represent real-world applied AI engineering.
In this article, we will break down the architecture behind an autonomous AI news pipeline and explore how the different layers work together to create a continuously operating AI-powered media system.
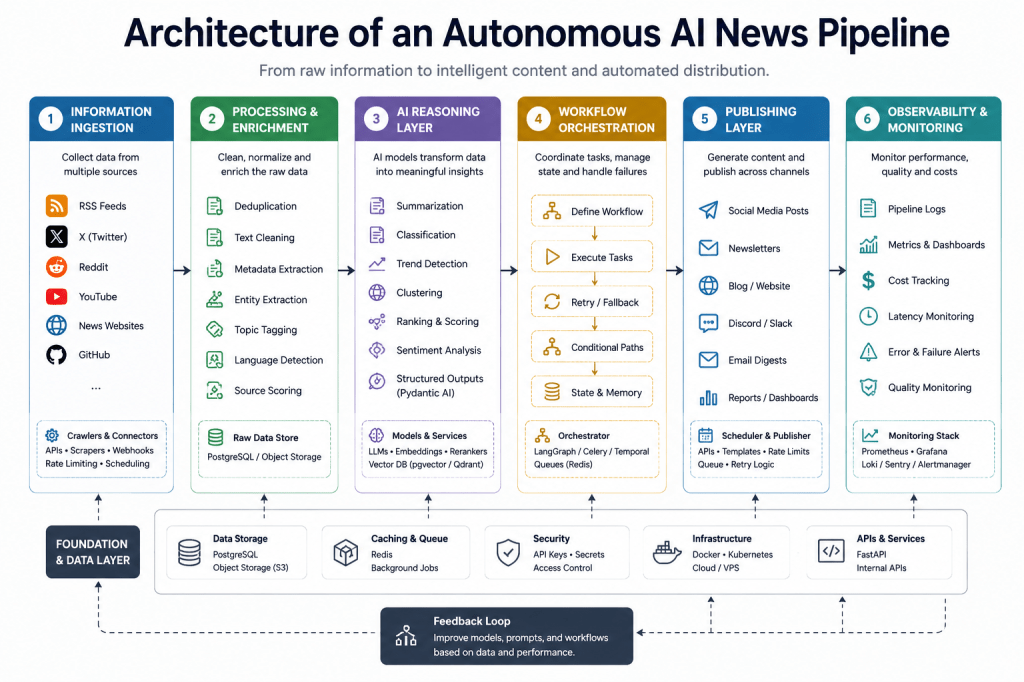
What Is an Autonomous AI News Pipeline?
An autonomous AI news pipeline is a workflow system that:
- collects information from external sources
- processes and analyzes that information using AI
- generates structured outputs or media content
- publishes or distributes the results automatically
The system operates continuously through scheduled workflows, event-driven triggers, or queue-based execution models.
Rather than relying on a human to manually gather and summarize information, the pipeline automates large portions of the media workflow.
Typical outputs include:
- AI news summaries
- trend reports
- social media posts
- newsletters
- research briefings
- blog drafts
- monitoring dashboards
High-Level Architecture Overview
A modern AI media pipeline is usually composed of several distinct layers:
- Information Ingestion Layer
- Processing & Enrichment Layer
- AI Reasoning Layer
- Workflow Orchestration Layer
- Publishing Layer
- Observability & Monitoring Layer
Each layer has different responsibilities and engineering challenges.
1. Information Ingestion Layer
The ingestion layer is responsible for collecting information from external sources.
This is the entry point of the pipeline.
Common Sources
Typical ingestion targets include:
- RSS feeds
- X/Twitter
- YouTube transcripts
- news websites
- APIs
- blogs
- newsletters
- GitHub repositories
Typical Technologies
The ingestion layer often uses:
- Playwright
- BeautifulSoup
- feedparser
- Selenium
- API clients
- webhook listeners
Responsibilities
The ingestion system usually handles:
- crawling
- scraping
- API communication
- rate limiting
- duplicate detection
- metadata extraction
- normalization
A major challenge at this stage is that every source has different formatting, structures, and reliability characteristics.
The ingestion layer must standardize all incoming information into a unified internal format.
For example:
{ "source": "reddit", "title": "New AI model released", "content": "...", "author": "user123", "timestamp": "2026-06-04", "url": "..."}
Standardization becomes essential for downstream AI processing.
2. Processing & Enrichment Layer
Once raw information enters the system, it must be cleaned and enriched.
Raw internet content is noisy.
It often contains:
- spam
- duplicates
- incomplete metadata
- irrelevant discussions
- low-quality content
- malformed HTML
The processing layer prepares the data for AI reasoning.
Typical Tasks
This layer often performs:
- text cleaning
- deduplication
- entity extraction
- keyword tagging
- language detection
- source scoring
- timestamp normalization
- content chunking
Why This Layer Matters
AI systems become unreliable when fed inconsistent or low-quality input.
Many production failures begin here.
Poor preprocessing can lead to:
- hallucinations
- irrelevant summaries
- duplicate outputs
- incorrect trend detection
- token waste
In many real-world systems, preprocessing quality matters more than prompt engineering.
3. AI Reasoning Layer
This is the intelligence core of the pipeline.
The reasoning layer transforms structured information into useful outputs.
Common AI Tasks
Typical operations include:
- summarization
- classification
- clustering
- trend detection
- sentiment analysis
- entity recognition
- ranking
- topic extraction
This layer often uses:
- OpenAI models
- embedding models
- vector databases
- reranking systems
- structured output frameworks
Multi-Step Reasoning
A single LLM call is often insufficient.
Modern pipelines frequently use chained reasoning steps:
- summarize article
- classify topic
- score importance
- compare against previous content
- generate social post
- generate newsletter summary
This is where orchestration frameworks become valuable.
4. Workflow Orchestration Layer
The orchestration layer coordinates the entire system.
This layer determines:
- what happens next
- which tasks run
- how retries work
- how failures are handled
- how state is maintained
Without orchestration, complex AI systems quickly become fragile.
Common Frameworks
Popular orchestration tools include:
- LangGraph
- Celery
- Temporal
- Prefect
- Apache Airflow
- custom queue systems
Why Orchestration Matters
Production AI systems are not linear.
They often require:
- retries
- branching logic
- conditional execution
- long-running workflows
- asynchronous processing
- state management
For example:
If summarization fails:
- retry with fallback model
If token limits are exceeded:
- split content into chunks
If trending score exceeds threshold:
- trigger social publishing workflow
This logic is the backbone of autonomous systems.
5. Publishing Layer
Once content is processed and generated, it must be distributed.
This layer handles external communication.
Common Outputs
Publishing targets may include:
Responsibilities
The publishing layer handles:
- formatting
- scheduling
- API posting
- media generation
- queue management
- retry logic
- content templating
This layer often includes human approval checkpoints to reduce the risk of publishing hallucinated or incorrect information.
6. Observability & Monitoring Layer
One of the most overlooked parts of AI systems is observability.
Autonomous pipelines require visibility into:
- token usage
- latency
- failures
- retries
- hallucinations
- throughput
- API errors
- cost tracking
Without observability, debugging becomes extremely difficult.
Monitoring Examples
A production system may track:
- cost per workflow
- failed pipeline stages
- average response latency
- summarization quality
- model reliability
- duplicate detection rates
Why Observability Is Critical
AI systems are probabilistic systems.
That means outputs can vary unexpectedly.
Monitoring becomes essential for:
- reliability
- optimization
- scaling
- debugging
- operational safety
Example Pipeline Flow
A simplified autonomous AI news pipeline may look like this:
RSS Feed → Content Extraction → Cleaning → Deduplication ↓Topic Classification → AI Summarization → Trend Scoring ↓Social Media Generation → Human Review → Auto Publishing ↓Logging → Metrics → Cost Tracking
Although simple in appearance, each stage may contain multiple internal workflows and decision systems.
Recommended Technology Stack
A modern AI media system might use a stack like this:
AI Layer
- OpenAI SDK
- LangGraph
- Pydantic AI
Backend
- FastAPI
- PostgreSQL
- Redis
Crawling
- Playwright
- BeautifulSoup
- feedparser
Infrastructure
- Docker
- Celery
- APScheduler
Monitoring
- logging systems
- tracing
- metrics dashboards
This stack provides a good balance between flexibility, scalability, and developer ergonomics.
Common Challenges in Autonomous AI Pipelines
Building these systems introduces many engineering challenges.
Hallucinations
AI-generated misinformation can propagate automatically if not validated.
Duplicate Content
News sources frequently overlap.
API Reliability
External APIs may fail, throttle, or change unexpectedly.
Token Costs
Large-scale summarization pipelines can become expensive quickly.
Workflow Failures
Multi-step pipelines require robust retry systems.
Latency
Complex orchestration increases processing time.
Scaling
As ingestion volume grows, queue systems and async workflows become necessary.
Understanding these problems is essential for production-grade AI engineering.
Why Autonomous AI Pipelines Matter
Autonomous AI pipelines represent an important shift in software engineering.
The industry is moving from:
- isolated prompts
toward:
- orchestrated intelligent systems
This transition changes how developers think about AI architecture.
The most valuable AI applications increasingly depend on:
- workflows
- coordination
- automation
- infrastructure
- observability
- reliability engineering
AI is no longer just a model.
It is becoming an operational system.
Final Thoughts
Autonomous AI news pipelines provide an excellent blueprint for understanding modern agentic systems.
They combine:
- AI reasoning
- orchestration
- automation
- infrastructure
- observability
- content generation
- workflow engineering
in one continuously operating architecture.
At AgenticMediaLab, we will continue exploring these systems in depth through real implementations, experiments, and engineering breakdowns.
The future of applied AI is not just better prompts.
It is better systems.
👉 You can experiment with a practical AI News System implementation of this concept in the official GitHub repository for the AgenticMediaLab: https://github.com/BenardoKemp/agentic-media-lab
